
Parsing binary data
Often, I've to parse simple binary protocols and in this article I describe the design pattern I often use to parse these binary protocols. They follow a couple of simple rules that you can apply to most binary protocols.
This code shows a simple, fast and easy to reproduce solution for parsing binary data. This technique is based on a couple of simple rules that are used in almost any application, file or protocol that stores binary data.
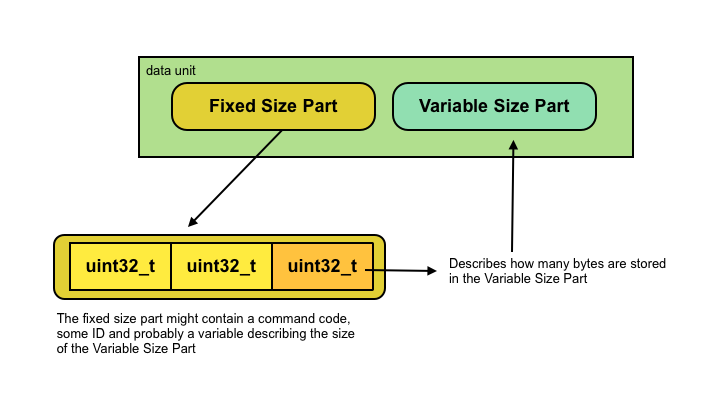
When someone writes binary data to a file or send it over the network it often contains a fixed-sized part and a variable-sized part. The technique in this document uses that information to create a fast, simple to implement parse function for that.
The parsing is based on a state machine; we keep track of the current state and read either the fixed-sized part, or the variable-sized + data part. I use the concept of data units, where a data-unit is build from: [ fixed-size + variable-size ]. For each data unit you create a two states, a SIZE and a READ state. For example: STATE_UPLOAD_SIZE and STATE_UPLOAD_READ.
SIZE: the size state checks if the buffer contains enough data for the fixed size part, and if it contains more (yes more) data then the fixed size, we read the fixed size. I say more, because we know that there will be more data that we need to parse, namely the [ variable-size ] part. After we've extracted the fixed-size part, we change the state to _READ where we read the actual data.
One thing which might be confusing, is that the fixed-size part, often contains information about how many bytes are stored in the variable-size part. So remember that the fixed-size part, is often just a uint32_t (or uint64_t) which contains the number of bytes stored in the variable-size part.
But that's not all.. the fixed size might also contains other, fixed size information, such as a COMMAND id (see below). In the example the fixed sizes contains the COMMAND id, which is stored as a uint32_t and the size of the string (also a uint32_t). Therefore the fixed size part in the code below is 8 bytes.
READ: once you've read the fixed size part and you know how many bytes are stored in the variable-sized we arrive in the _READ state, copy/process the data and change the state again. Note that we need to check if the buffer has the exact amount or more (>=) bytes stored, that we're looking for.
The other part of parsing relates to how we actually write a
parse function. I tend to a simple switch() where I switch
between states. Then I wrap this switch around a while(buffer.size())
loop so it will parse all data - or until only part of the data is
stored in the buffer. Note that I follow simple rules for the separate
cases which prevent getting in a never-ending loop. These are:
- in each case, check if the buffer contains enough bytes that you need; when there are not enough bytes return immediately!
- when there is enough data, *read the data** and flush the bytes you've read so the buffer size reduces.
- add a
default:case where you return.
So a generic parse loop and case looks like:
int data_size = 0; while(buffer.size()) { switch(state) { case STATE_ENCODE_SIZE: { if(buffer.size() > 8) { // read the variable-size part here, and store it in data_size + change state buffer.erase(buffer.begin(), buffer.begin() + 8); // erase fixed size break; } return; } case STATE_ENCODE_READ: { if(buffer.size() >= data_size) { // read the variable data size here buffer.erase(buffer.begin(), buffer.begin() + data_size); // erase variable sized data break; } return; } } }
Working example
// tested on Mac 10.8, compile with: g++ main.cpp -o out #include <iostream> #include <vector> #include <string> #include <iterator> #include <algorithm> #include <stdint.h> #define COMMAND_STRING 0x01 #define COMMAND_PERSON 0x02 #define STATE_STRING_SIZE 1 #define STATE_STRING_READ 2 int state = STATE_STRING_SIZE; uint32_t data_size = 0; struct person { std::string name; std::string address; }; // ----------------------------------------------- void parse(std::vector<char>& buffer); void put_u32(std::vector<char>& buffer, uint32_t d); void put_string(std::vector<char>& buffer, std::string str); void put_bytes(std::vector<char>& buffer, const char* data, size_t nbytes); int main() { printf("Binary Buffer Parsing Example\n"); std::vector<char> buffer; // store a string std::string some_string = "This is just some string"; put_u32(buffer, COMMAND_STRING); put_string(buffer, some_string); // store a person person p; p.name = "roxlu"; p.address = "Amsterdam"; put_u32(buffer, COMMAND_PERSON); put_string(buffer, p.name); put_u32(buffer, COMMAND_PERSON); // our super simple protocol is based on [command] [string size] [string], so must repeat the command for each person string put_string(buffer, p.address); // parse the buffer printf("Buffer contains: %ld bytes\n", buffer.size()); parse(buffer); return EXIT_SUCCESS; } void parse(std::vector<char>& buffer) { while(buffer.size()) { switch(state) { // STEP 1: parse the fixed size length case STATE_STRING_SIZE: { if(buffer.size() > 8) { // always use > and not >= for the fixed-size check, because this should only success when the buffer has more data then just the size (e.g. the string itself) memcpy((char*)&data_size, &buffer[4], 4); // always start reading from [0] because we always cleanup the data after us. note that we're not reading the command that we've added above (COMMAND_STRING), but we know that COMMAND_STRING = 4 bytes (uint32_t) and a string also stores at least 4 bytes so the fixed size is always 8 buffer.erase(buffer.begin(), buffer.begin() + 8); // and flush the buffer state = STATE_STRING_READ; printf("+ %d\n", data_size); break; } return; } // STEP 2: parse the variable size length case STATE_STRING_READ: { if(buffer.size() >= data_size) { // when reading the data part, use >= and not > because we might receive the -exact- amount of data OR more (the buffer could contain the next command) std::string str((char*)&buffer[0], data_size); buffer.erase(buffer.begin(), buffer.begin() + data_size); // and flush the buffer! state = STATE_STRING_SIZE; // because our parser only handles one type of command we set it back to the read size state printf("> %s\n", str.c_str()); break; } return; } default: { return; } } } } void put_u32(std::vector<char>&buffer, uint32_t d) { char* ptr = (char*)&d; std::copy(ptr, ptr+4, std::back_inserter(buffer)); } void put_string(std::vector<char>& buffer, std::string str) { if(str.size()) { put_u32(buffer, str.size()); put_bytes(buffer, str.c_str(), str.size()); } } void put_bytes(std::vector<char>& buffer, const char* data, size_t nbytes) { std::copy(data, data+nbytes, std::back_inserter(buffer)); }
 NAT Types
NAT Types
 Building Cabinets
Building Cabinets
 Compiling GStreamer from source on Windows
Compiling GStreamer from source on Windows
 Debugging CMake Issues
Debugging CMake Issues
 Dual Boot Arch Linux and Windows 10
Dual Boot Arch Linux and Windows 10
 Mindset Updated Edition, Carol S. Dweck (Book Notes)
Mindset Updated Edition, Carol S. Dweck (Book Notes)
 How to setup a self-hosted Unifi NVR with Arch Linux
How to setup a self-hosted Unifi NVR with Arch Linux
 Blender 2.8 How to use Transparent Textures
Blender 2.8 How to use Transparent Textures
 Compiling FFmpeg with X264 on Windows 10 using MSVC
Compiling FFmpeg with X264 on Windows 10 using MSVC
 Blender 2.8 OpenGL Buffer Exporter
Blender 2.8 OpenGL Buffer Exporter
 Blender 2.8 Baking lightmaps
Blender 2.8 Baking lightmaps
 Blender 2.8 Tips and Tricks
Blender 2.8 Tips and Tricks
 Setting up a Bluetooth Headset on Arch Linux
Setting up a Bluetooth Headset on Arch Linux
 Compiling x264 on Windows with MSVC
Compiling x264 on Windows with MSVC
 C/C++ Snippets
C/C++ Snippets
 Reading Chunks from a Buffer
Reading Chunks from a Buffer
 Handy Bash Commands
Handy Bash Commands
 Building a zero copy parser
Building a zero copy parser
 Kalman Filter
Kalman Filter
 Saving pixel data using libpng
Saving pixel data using libpng
 Compile Apache, PHP and MySQL on Mac 10.10
Compile Apache, PHP and MySQL on Mac 10.10
 Fast Pixel Transfers with Pixel Buffer Objects
Fast Pixel Transfers with Pixel Buffer Objects
 High Resolution Timer function in C/C++
High Resolution Timer function in C/C++
 Rendering text with Pango, Cairo and Freetype
Rendering text with Pango, Cairo and Freetype
 Fast OpenGL blur shader
Fast OpenGL blur shader
 Spherical Environment Mapping with OpenGL
Spherical Environment Mapping with OpenGL
 Using OpenSSL with memory BIOs
Using OpenSSL with memory BIOs
 Attributeless Vertex Shader with OpenGL
Attributeless Vertex Shader with OpenGL
 Circular Image Selector
Circular Image Selector
 Decoding H264 and YUV420P playback
Decoding H264 and YUV420P playback
 Fast Fourier Transform
Fast Fourier Transform
 OpenGL Rim Shader
OpenGL Rim Shader
 Rendering The Depth Buffer
Rendering The Depth Buffer
 Delaunay Triangulation
Delaunay Triangulation
 RapidXML
RapidXML
 Git Snippets
Git Snippets
 Basic Shading With OpenGL
Basic Shading With OpenGL
 Open Source Libraries For Creative Coding
Open Source Libraries For Creative Coding
 Bouncing particle effect
Bouncing particle effect
 OpenGL Instanced Rendering
OpenGL Instanced Rendering
 Mapping a texture on a disc
Mapping a texture on a disc
 Download HTML page using CURL
Download HTML page using CURL
 Height Field Simulation on GPU
Height Field Simulation on GPU
 OpenCV
OpenCV
 Some notes on OpenGL
Some notes on OpenGL
 Math
Math
 Gists to remember
Gists to remember
 Reverse SSH
Reverse SSH
 Working Set
Working Set
 Consumer + Producer model with libuv
Consumer + Producer model with libuv
 Parsing binary data
Parsing binary data
 C++ file operation snippets
C++ file operation snippets
 Importance of blur with image gradients
Importance of blur with image gradients
 Real-time oil painting with openGL
Real-time oil painting with openGL
 x264 encoder
x264 encoder
 Generative helix with openGL
Generative helix with openGL
 Mini test with vector field
Mini test with vector field
 Protractor gesture recognizer
Protractor gesture recognizer
 Hair simulation
Hair simulation
 Some glitch screenshots
Some glitch screenshots
 Working on video installation
Working on video installation
 Generative meshes
Generative meshes
 Converting video/audio using avconv
Converting video/audio using avconv
 Auto start terminal app on mac
Auto start terminal app on mac
 Export blender object to simple file format
Export blender object to simple file format